P2P Data Sync with a Remote Log
A research log. Asynchronous P2P messaging? Remote logs to the rescue!
A big problem when doing end-to-end data sync between mobile nodes is that most devices are offline most of the time. With a naive approach, you quickly run into issues of 'ping-pong' behavior, where messages have to be constantly retransmitted. We saw some basic calculations of what this bandwidth multiplier looks like in a previous post.
While you could do some background processing, this is really battery-draining, and on iOS these capabilities are limited. A better approach instead is to loosen the constraint that two nodes need to be online at the same time. How do we do this? There are two main approaches, one is the store and forward model, and the other is a remote log.
In the store and forward model, we use an intermediate node that forward messages on behalf of the recipient. In the remote log model, you instead replicate the data onto some decentralized storage, and have a mutable reference to the latest state, similar to DNS. While both work, the latter is somewhat more elegant and "pure", as it has less strict requirements of an individual node's uptime. Both act as a highly-available cache to smoothen over non-overlapping connection windows between endpoints.
In this post we are going to describe how such a remote log schema could work. Specifically, how it enhances p2p data sync and takes care of the following requirements:
- MUST allow for mobile-friendly usage. By mobile-friendly we mean devices that are resource restricted, mostly-offline and often changing network.
- MAY use helper services in order to be more mobile-friendly. Examples of helper services are decentralized file storage solutions such as IPFS and Swarm. These help with availability and latency of data for mostly-offline devices.
Remote log
A remote log is a replication of a local log. This means a node can read data from a node that is offline.
The spec is in an early draft stage and can be found here. A very basic spike / proof-of-concept can be found here.
Definitions
| Term | Definition |
|---|---|
| CAS | Content-addressed storage. Stores data that can be addressed by its hash. |
| NS | Name system. Associates mutable data to a name. |
| Remote log | Replication of a local log at a different location. |
Roles
There are four fundamental roles:
- Alice
- Bob
- Name system (NS)
- Content-addressed storage (CAS)
The remote log is the data format of what is stored in the name system.
"Bob" can represent anything from 0 to N participants. Unlike Alice, Bob only needs read-only access to NS and CAS.
Flow
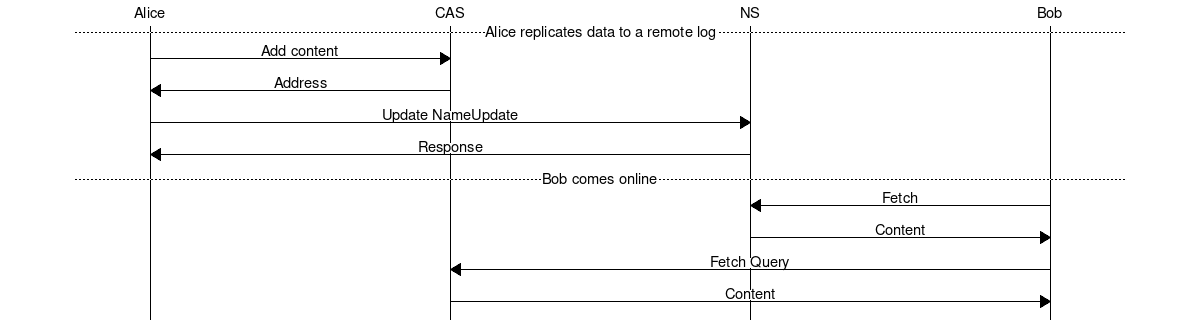
Data format
The remote log lets receiving nodes know what data they are missing. Depending on the specific requirements and capabilities of the nodes and name system, the information can be referred to differently. We distinguish between three rough modes:
- Fully replicated log
- Normal sized page with CAS mapping
- "Linked list" mode - minimally sized page with CAS mapping
A remote log is simply a mapping from message identifiers to their corresponding address in a CAS:
| Message Identifier (H1) | CAS Hash (H2) |
|---|---|
| H1_3 | H2_3 |
| H1_2 | H2_2 |
| H1_1 | H2_1 |
| address to next page |
The numbers here corresponds to messages. Optionally, the content itself can be included, just like it normally would be sent over the wire. This bypasses the need for a dedicated CAS and additional round-trips, with a trade-off in bandwidth usage.
| Message Identifier (H1) | Content |
|---|---|
| H1_3 | C3 |
| H1_2 | C2 |
| H1_1 | C1 |
| address to next page |
Both patterns can be used in parallel, e,g. by storing the last k messages directly and use CAS pointers for the rest. Together with the next_page page semantics, this gives users flexibility in terms of bandwidth and latency/indirection, all the way from a simple linked list to a fully replicated log. The latter is useful for things like backups on durable storage.
Interaction with MVDS
vac.mvds.Message payloads are the only payloads that MUST be uploaded. Other messages types MAY be uploaded, depending on the implementation.
Future work
The spec is still in an early draft stage, so it is expected to change. Same with the proof of concept. More work is needed on getting a fully featured proof of concept with specific CAS and NAS instances. E.g. Swarm and Swarm Feeds, or IPFS and IPNS, or something else.
For data sync in general:
- Make consistency guarantees more explicit for app developers with support for sequence numbers and DAGs, as well as the ability to send non-synced messages. E.g. ephemeral typing notifications, linear/sequential history and casual consistency/DAG history
- Better semantics and scalability for multi-user sync contexts, e.g. CRDTs and joining multiple logs together
- Better usability in terms of application layer usage (data sync clients) and supporting more transports
PS1. Thanks everyone who submitted great logo proposals for Vac!
PPS2. Next week on October 10th decanus and I will be presenting Vac at Devcon, come say hi :)