Building Privacy-Protecting Infrastructure
What is privacy-protecting infrastructure? Why do we need it and how we can build it? We'll look at Waku, the communication layer for Web3. We'll see how it uses ZKPs to incentivize and protect the Waku network. We'll also look at Zerokit, a library that makes it easier to use ZKPs in different environments. After reading this, I hope you'll better understand the importance of privacy-protecting infrastructure and how we can build it.
This write-up is based on a talk given at DevCon 6 in Bogota, a video can be found here
Intro
In this write-up, we are going to talk about building privacy-protecting infrastructure. What is it, why do we need it and how can we build it?
We'll look at Waku, the communication layer for Web3. We'll look at how we are using Zero Knowledge (ZK) technology to incentivize and protect the Waku network. We'll also look at Zerokit, a library we are writing to make ZKP easier to use in different environments.
At the end of this write-up, I hope you'll come away with an understanding of the importance of privacy-protecting infrastructure and how we can build it.
About
First, briefly about Vac. We build public good protocols for the decentralized web, with a focus on privacy and communication. We do applied research based on which we build protocols, libraries and publications. We are also the custodians of protocols that reflect a set of principles.
It has its origins in the Status app and trying to improve the underlying protocols and infrastructure. We build Waku, among other things.
Why build privacy-protecting infrastructure?
Privacy is the power to selectively reveal yourself. It is a requirement for freedom and self-determination.
Just like you need decentralization in order to get censorship-resistance, you need privacy to enable freedom of expression.
To build applications that are decentralized and privacy-protecting, you need the base layer, the infrastructure itself, to have those properties.
We see this a lot. It is easier to make trade-offs at the application layer than doing them at the base layer. You can build custodial solutions on top of a decentralized and non-custodial network where participants control their own keys, but you can't do the opposite.
If you think about it, buildings can be seen as a form of privacy-protecting infrastructure. It is completely normal and obvious in many ways, but when it comes to the digital realm our mental models and way of speaking about it hasn't caught up yet for most people.
I'm not going too much more into the need for privacy or what happens when you don't have it, but suffice to say it is an important property for any open society.
When we have conversations, true peer-to-peer offline conversations, we can talk privately. If we use cash to buy things we can do commerce privately.
On the Internet, great as it is, there are a lot of forces that makes this natural state of things not the default. Big Tech has turned users into a commodity, a product, and monetized user's attention for advertising. To optimize for your attention they need to surveil your habits and activities, and hence breach your privacy. As opposed to more old-fashioned models, where someone is buying a useful service from a company and the incentives are more aligned.
We need to build credibly neutral infrastructure that protects your privacy at the base layer, in order to truly enable applications that are censorship-resistant and encourage meaningful freedom of expression.
Web3 infrastructure
Infrastructure is what lies underneath. Many ways of looking at this but I'll keep it simple as per the original Web3 vision. You had Ethereum for compute/consensus, Swarm for storage, and Whisper for messaging. Waku has taken over the mantle from Whisper and is a lot more usable today than Whisper ever was, for many reasons.
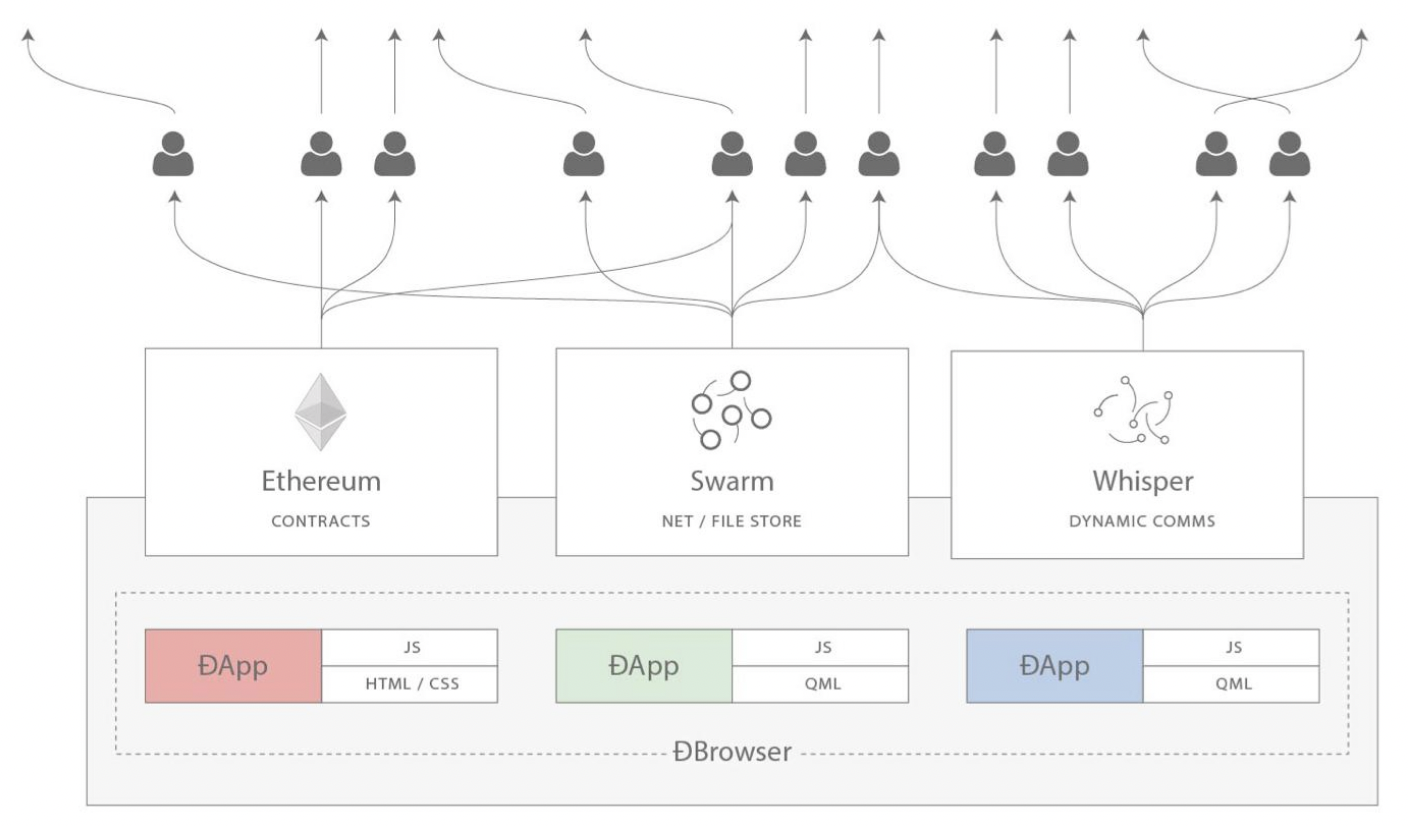
On the privacy-front, we see how Ethereum is struggling. It is a big UX problem, especially when you try to add privacy back "on top". It takes a lot of effort and it is easier to censor. We see this with recent action around Tornado Cash. Compare this with something like Zcash or Monero, where privacy is there by default.
There are also problems when it comes to the p2p networking side of things, for example with Ethereum validator privacy and hostile actors and jurisdictions. If someone can easily find out where a certain validator is physically located, that's a problem in many parts of the world. Being able to have stronger privacy-protection guarantees would be very useful for high-value targets.
This doesn't begin to touch on the so called "dapps" that make a lot of sacrifices in how they function, from the way domains work, to how websites are hosted and the reliance on centralized services for communication. We see this time and time again, where centralized, single points of failure systems work for a while, but then eventually fail.
In many cases an individual user might not care enough though, and for platforms the lure to take shortcuts is strong. That is why it is important to be principled, but also pragmatic in terms of the trade-offs that you allow on top. We'll touch more on this in the design goals around modularity that Waku has.
ZK for privacy-protecting infrastructure
ZKPs are a wonderful new tool. Just like smart contracts enables programmable money, ZKPs allow us to express fundamentally new things. In line with the great tradition of trust-minimization, we can prove statement while revealing the absolute minimum information necessary. This fits the definition of privacy, the power to selectively reveal yourself, perfectly. I'm sure I don't need to tell anyone reading this but this is truly revolutionary. The technology is advancing extremely fast and often it is our imagination that is the limit.

Waku
What is Waku? It is a set of modular protocols for p2p communication. It has a focus on privacy, security and being able to run anywhere. It is the spiritual success to Whisper.
By modular we mean that you can pick and choose protocols and how you use them depending on constraints and trade-offs. For example, bandwidth usage vs privacy.
It is designed to work in resource restricted environments, such as mobile phones and in web browsers. It is important that infrastructure meets users where they are and supports their real-world use cases. Just like you don't need your own army and a castle to have your own private bathroom, you shouldn't need to have a powerful always-on node to get reasonable privacy and censorship-resistance. We might call this self-sovereignty.
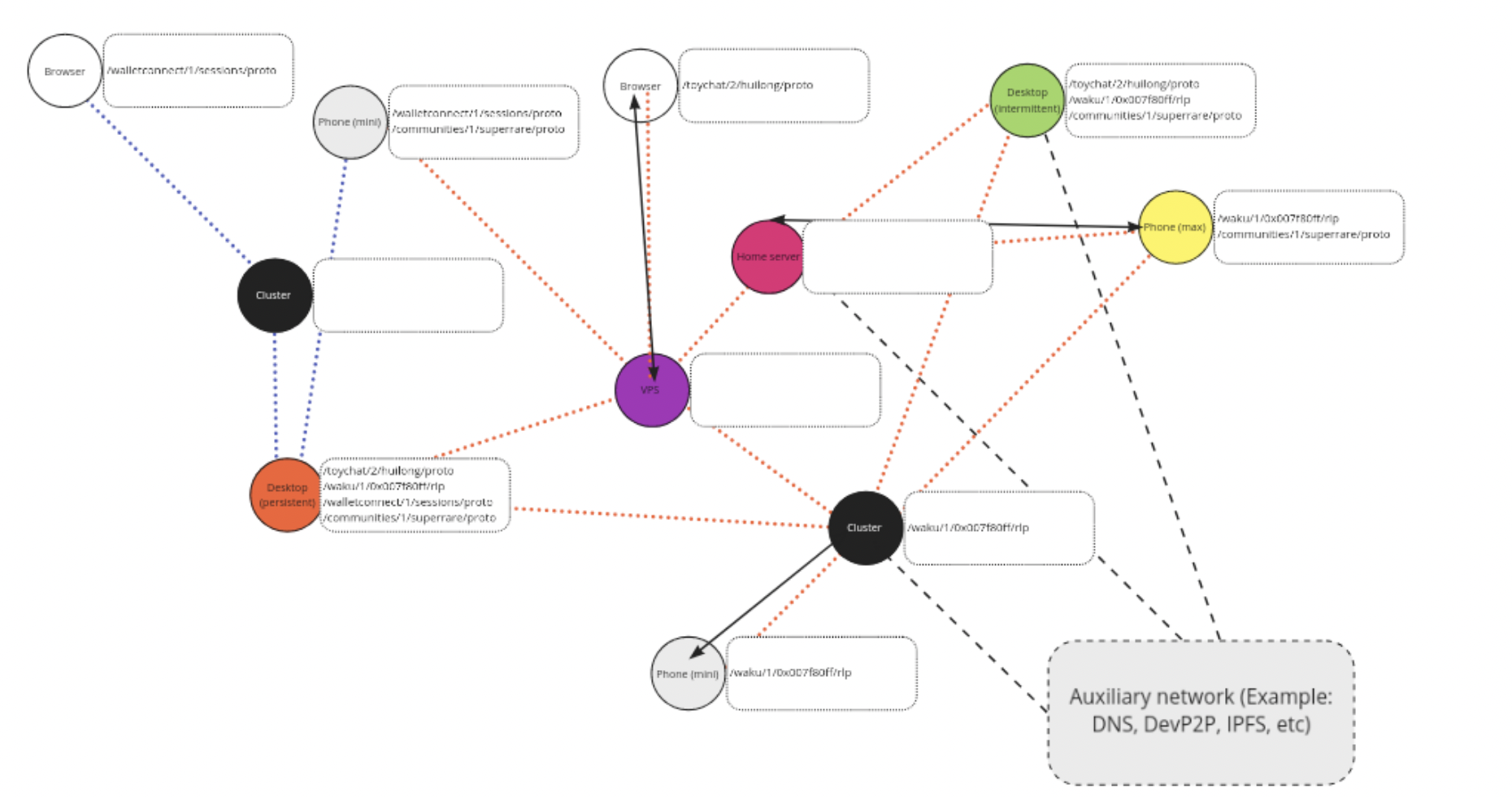
Waku - adaptive nodes
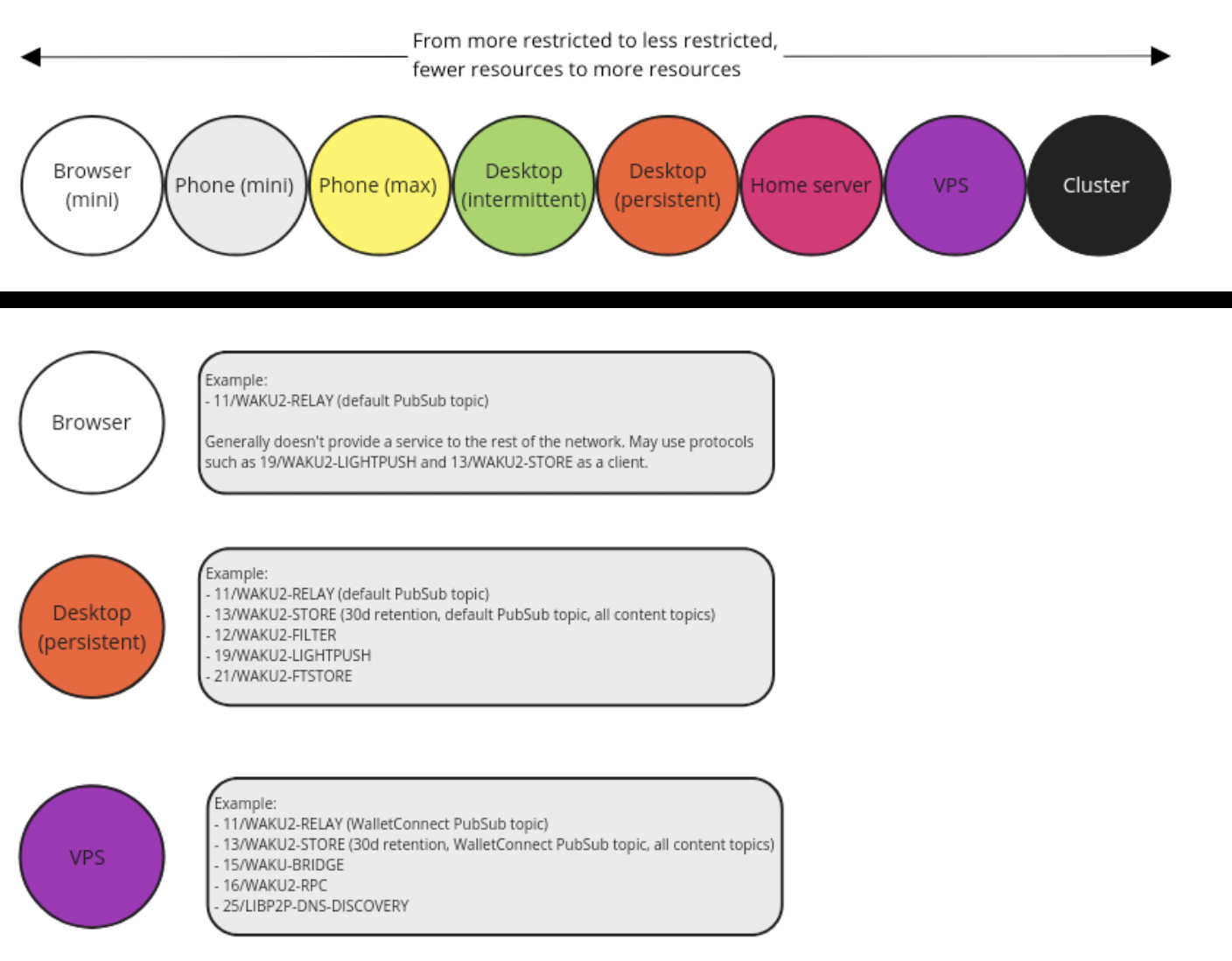
One way of looking at Waku is as an open service network. There are nodes with varying degrees of capabilities and requirements. For example when it comes to bandwidth usage, storage, uptime, privacy requirements, latency requirements, and connectivity restrictions.
We have a concept of adaptive nodes that can run a variety of protocols. A node operator can choose which protocols they want to run. Naturally, there'll be some nodes that do more consumption and other nodes that do more provisioning. This gives rise to the idea of a service network, where services are provided for and consumed.
Waku - protocol interactions
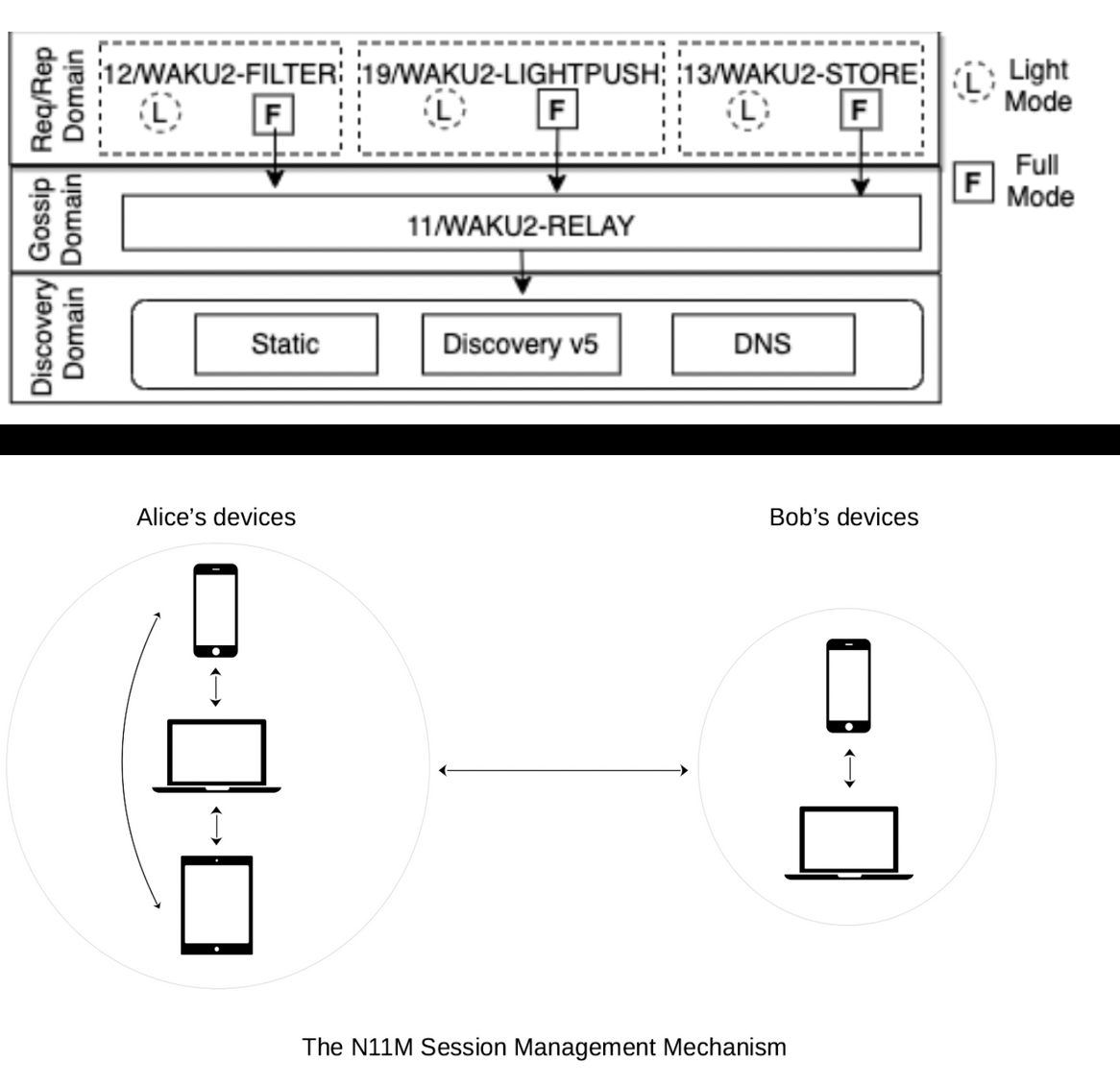
There are many protocols that interact. Waku Relay protocol is based on libp2p GossipSub for p2p messaging. We have filter for bandwidth-restricted nodes to only receive subset of messages. Lightpush for nodes with short connection windows to push messages into network. Store for nodes that want to retrieve historical messages.
On the payload layer, we provide support for Noise handshakes/key-exchanges. This means that as a developers, you can get end-to-end encryption and expected guarantees out of the box. We have support for setting up a secure channel from scratch, and all of this paves the way for providing Signal's Double Ratchet at the protocol level much easier. We also have experimental support for multi-device usage. Similar features have existed in for example the Status app for a while, but with this we make it easier for any platform using Waku to use it.
There are other protocols too, related to peer discovery, topic usage, etc. See specs for more details.
Waku - Network
For the Waku network, there are a few problems. For example, when it comes to network spam and incentivizing service nodes. We want to address these while keeping privacy-guarantees of the base layer. I'm going to go into both of these.
The spam problem arises on the gossip layer when anyone can overwhelm the network with messages. The service incentivization is a problem when nodes don't directly benefit from the provisioning of a certain service. This can happen if they are not using the protocol directly themselves as part of normal operation, or if they aren't socially inclined to provide a certain service. This depends a lot on how an individual platform decides to use the network.
Dealing with network spam and RLN Relay
Since the p2p relay network is open to anyone, there is a problem with spam. If we look at existing solutions for dealing with spam in traditional messaging systems, a lot of entities like Google, Facebook, Twitter, Telegram, Discord use phone number verification. While this is largely sybil-resistant, it is centralized and not private at all.
Historically, Whisper used PoW which isn't good for heterogenerous networks. Peer scoring is open to sybil attacks and doesn't directly address spam protection in an anonymous p2p network.
The key idea here is to use RLN for private economic spam protection using zkSNARKs.
I'm not going to go into too much detail of RLN here. If you are interested, I gave a talk in Amsterdam at Devconnect about this. We have some write-ups on RLN here by Sanaz who has been pushing a lot of this from our side. There's also another talk at Devcon by Tyler going into RLN in more detail. Finally, here's the RLN spec.
I'll briefly go over what it is, the interface and circuit and then talk about how it is used in Waku.
RLN - Overview and Flow
RLN stands for Rate Limiting Nullifier. It is an anonyomous rate limiting mechanism based on zkSNARKs. By rate limiting we mean you can only send N messages in a given period. By anonymity we mean that you can't link message to a publisher. We can think of it as a voting booth, where you are only allowed to vote once every election.

It can be used for spam protection in p2p messaging systems, and also rate limiting in general, such as for a decentralized captcha.
There are three parts to it. You register somewhere, then you can signal and finally there's a verification/slashing phase. You put some capital at risk, either economic or social, and if you double signal you get slashed.
RLN - Circuit
Here's what the private and public inputs to the circuit look like. The identity secret is generated locally, and we create an identity commitment that is inserted into a Merkle tree. We then use Merkle proofs to prove membership. Registered member can only signal once for a given epoch or external nullifier, for example every ten seconds in Unix time. RLN identifer is for a specific RLN app.
We also see what the circuit output looks like. This is calculated locally. y
is a share of the secret equation, and the (internal) nullifier acts as a unique
fingerprint for a given app/user/epoch combination. How do we calculate y and
the internal nullifier?
// Private input
signal input identity_secret;
signal input path_elements[n_levels][1];
signal input identity_path_index[n_levels];
// Public input
signal input x; // signal_hash
signal input epoch; // external_nullifier
signal input rln_identifier;
// Circuit output
signal output y;
signal output root;
signal output nullifier;
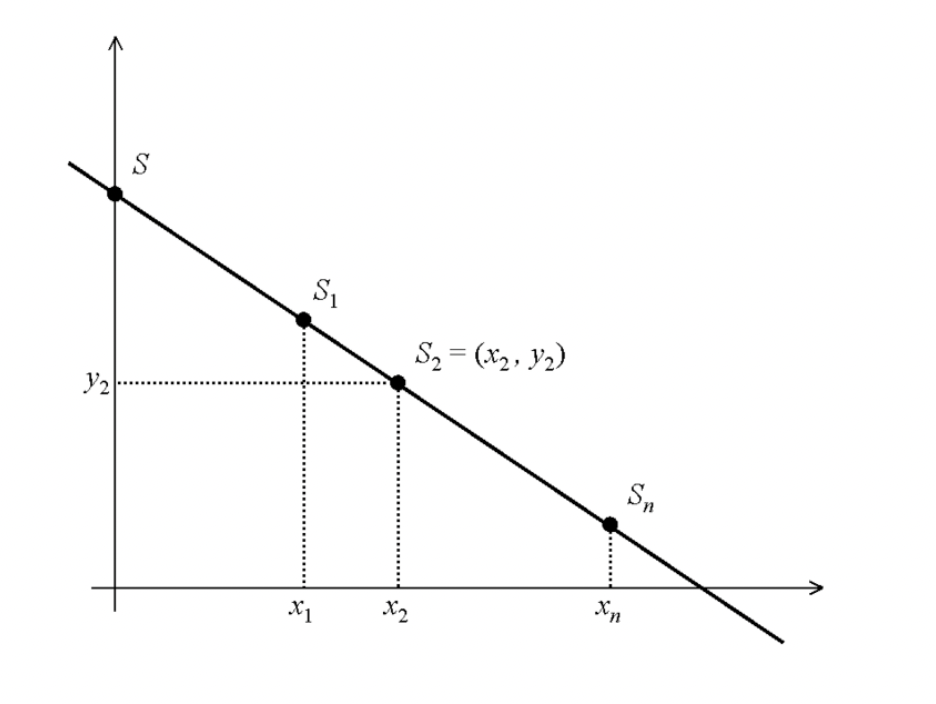
RLN - Shamir's secret sharing
This is done using Shamir's secret sharing. Shamir’s secret sharing is based on idea of splitting a secret into shares. This is how we enable slashing of funds.
In this case, we have two shares. If a given identity a0 signals twice in
epoch/external nullifier, a1 is the same. For a given RLN app,
internal_nullifier then stays the same. x is signal hash which is different,
and y is public, so we can reconstruct identity_secret. With the identity
secret revealed, this gives access to e.g. financial stake.
a_0 = identity_secret // secret S
a_1 = poseidonHash([a0, external_nullifier])
y = a_0 + x * a_1
internal_nullifier = poseidonHash([a_1, rln_identifier])
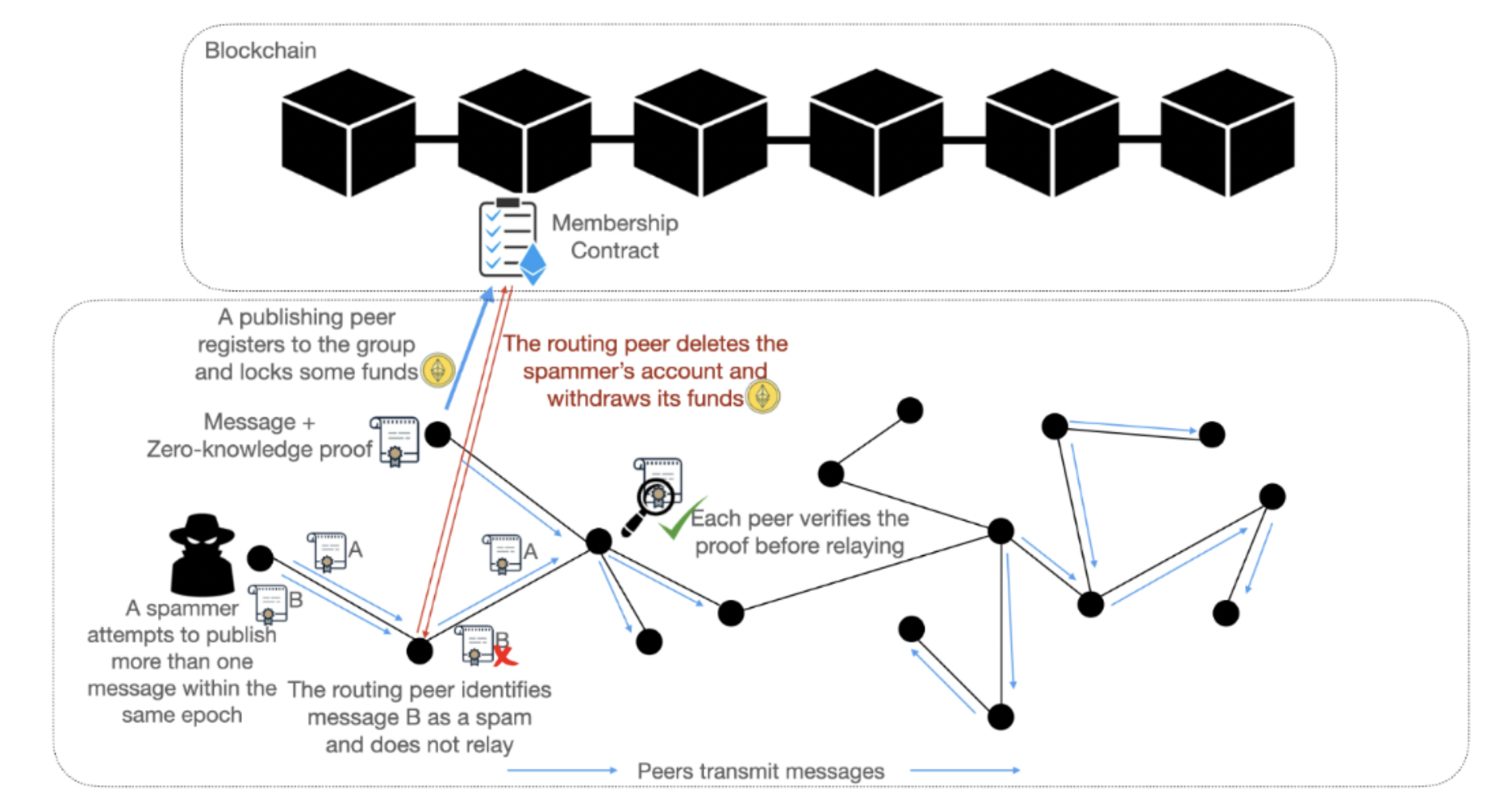
RLN Relay
This is how RLN is used with Relay/GossipSub protocol. A node registers and locks up funds, and after that it can send messages. It publishes a message containing the Zero Knowledge proof and some other details.
Each relayer node listens to the membership contract for new members, and it also keeps track of relevant metadata and merkle tree. Metadata is needed to be able to detect double signaling and perform slashing.
Before forwarding a message, it does some verification checks to ensure there are no duplicate messages, ZKP is valid and no double signaling has occured. It is worth noting that this can be combined with peer scoring, for example for duplicate messages or invalid ZK proofs.
In line of Waku's goals of modularity, RLN Relay is applied on a specific subset of pubsub and content topics. You can think of it as an extra secure channel.
RLN Relay cross-client testnet
Where are we with RLN Relay deployment? We've recently launched our second testnet. This is using RLN Relay with a smart contract on Goerli. It integrates with our example p2p chat application, and it does so through three different clients, nwaku, go-waku and js-waku for browsers. This is our first p2p cross-client testnet for RLN Relay.
Here's a video that shows a user registering in a browser, signaling through JS-Waku. It then gets relayed to a nwaku node, that verifies the proof. The second video shows what happens in the spam case. when more than one message is sent in a given epoch, it detects it as spam and discards it. Slashing hasn't been implemented fully yet in the client and is a work in progress.
If you are curious and want to participate, you can join the effort on our Vac Discord. We also have tutorials setup for all clients so you can play around with it.
As part of this, and to make it work in multiple different environments, we've also been developing a new library called Zerokit. I'll talk about this a bit later.
Private settlement / Service credentials
Going back to the service network idea, let's talk about service credentials. The idea behind service credentials and private settlement is to enable two actors to pay for and provide services without compromising their privacy. We do not want the payment to create a direct public link between the service provider and requester.
Recall the Waku service network illustration with adaptive nodes that choose which protocols they want to run. Many of these protocols aren't very heavy and just work by default. For example the relay protocol is enabled by default. Other protocols are much heavier to provide, such as storing historical messages.
It is desirable to have additional incentives for this, especially for platforms that aren't community-based where some level of altruism can be assumed (e.g. Status Communities, or WalletConnect cloud infrastructure).
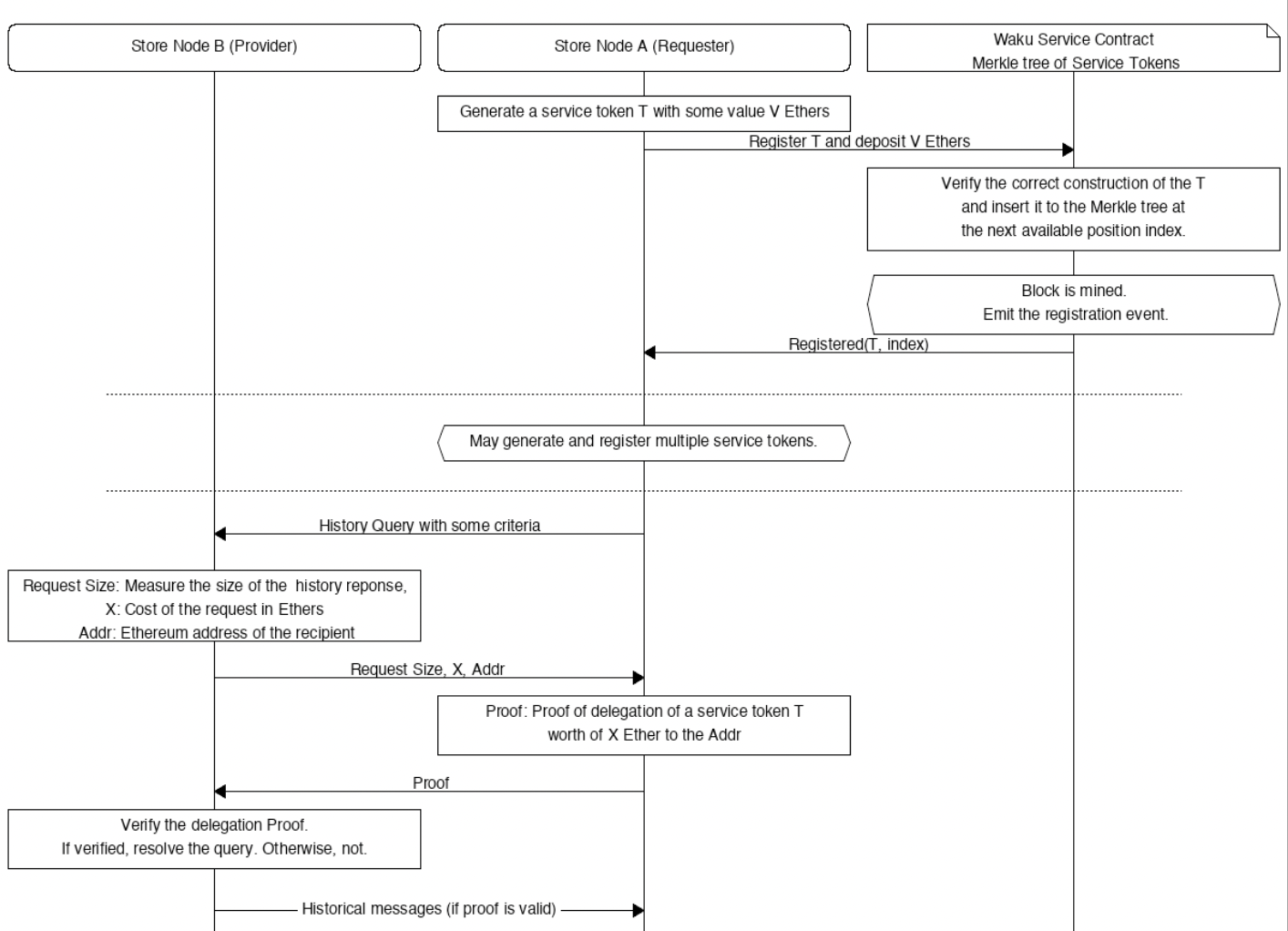
You have a node Alice that is often offline and wants to consume historical messages on some specific content topics. You have another node Bob that runs a server at home where they store historical messages for the last several weeks. Bob is happy to provide this service for free because he's excited about running privacy-preserving infrastructure and he's using it himself, but his node is getting overwhelmed by freeloaders and he feels like he should be paid something for continuing to provide this service.
Alice deposits some funds in a smart contract which registers it in a tree, similar to certain other private settlement mechanisms. A fee is taken or burned. In exchange, she gets a set of tokens or service credentials. When she wants to do a query with some criteria, she sends this to Bob. Bob responds with size of response, cost, and receiver address. Alice then sends a proof of delegation of a service token as a payment. Bob verifies the proof and resolves the query.
The end result is that Alice has consumed some service from Bob, and Bob has received payment for this. There's no direct transaction link between Alice and Bob, and gas fees can be minimized by extending the period before settling on chain.
This can be complemented with altruistic service provisioning, for example by splitting the peer pool into two slots, or only providing a few cheap queries for free.
The service provisioning is general, and can be generalized for any kind of request/response service provisoning that we want to keep private.
This isn't a perfect solution, but it is an incremental improvement on top of the status quo. It can be augmented with more advanced techniques such as better non-repudiable node reputation, proof of correct service provisioning, etc.
We are currently in the raw spec / proof of concept stage of this. We expect to launch a testnet of this later this year or early next year.
Zerokit
Zerokit is a set of Zero Knowledge modules, written in Rust and designed to be used in many different environments. The initial goal is to get the best of both worlds with Circom/Solidity/JS and Rust/ZK ecosystem. This enables people to leverage Circom-based constructs from non-JS environments.
For the RLN module, it is using Circom circuits via ark-circom and Rust for scaffolding. It exposes a C FFI API that can be used through other system programming environments, like Nim and Go. It also exposes an experimental WASM API that can be used through web browsers.
Waku is p2p infrastructure running in many different environments, such as Nim/JS/Go/Rust, so this a requirement for us.
Circom and JS strengths are access to Dapp developers, tooling, generating verification code, circuits etc. Rust strengths is that it is systems-based and easy to interface with other language runtime such as Nim, Go, Rust, C. It also gives access to other Rust ZK ecosystems such as arkworks. This opens door for using other constructs, such as Halo2. This becomes especially relevant for constructs where you don't want to do a trusted setup or where circuits are more complex/custom and performance requirements are higher.
In general with Zerokit, we want to make it easy to build and use ZKP in a multitude of environments, such as mobile phones and web browsers. Currently it is too complex to write privacy-protecting infrastructure with ZKPs considering all the languages and tools you have to learn, from JS, Solidity and Circom to Rust, WASM and FFI. And that isn't even touching on things like secure key storage or mobile dev. Luckily more and more projects are working on this, including writing DSLs etc. It'd also be exciting if we can make a useful toolstack for JS-less ZK dev to reduce cognitive overhead, similar to what we have with something like Foundry.
Other research
I also want to mention a few other things we are doing. One thing is protocol specifications. We think this is very important for p2p infra, and we see a lot of other projects that claim to do it p2p infrastructure but they aren't clear about guarantees or how stable something is. That makes it hard to have multiple implementations, to collaborate across different projects, and to analyze things objectively.
Related to that is publishing papers. We've put out three so far, related to Waku and RLN-Relay. This makes it easier to interface with academia. There's a lot of good researchers out there and we want to build a better bridge between academia and industry.
Another thing is network privacy. Waku is modular with respect to privacy guarantees, and there are a lot of knobs to turn here depending on specific deployments. For example, if you are running the full relay protocol you currently have much stronger receiver anonymity than if you are running filter protocol from a bandwidth or connectivity-restricted node.
We aim to make this pluggable depending on user needs. E.g. mixnets such as Nym come with some trade-offs but are a useful tool in the arsenal. A good mental model to keep in mind is the anonymity trilemma, where you can only pick 2/3 out of low latency, low bandwidth usage and strong anonymity.
We are currently exploring Dandelion-like additions to the relay/gossip protocol, which would provide for stronger sender anonymity, especially in a multi-node/botnet attacker model. As part of this we are looking into different parameters choices and general possibilities for lower latency usage. This could make it more amenable for latency sensitive environments, such as validator privacy, for specific threat models. The general theme here is we want to be rigorous with the guarantees we provide, under what conditions and for what threat models.
Another thing mentioned earlier is Noise payload encryption, and specifically things like allowing for pairing different devices with e.g. QR codes. This makes it easier for developers to provide secure messaging in many realistic scenarios in a multi-device world.

Summary
We've gone over what privacy-protecting infrastructure is, why we want it and how we can build it. We've seen how ZK is a fundamental building block for this. We've looked at Waku, the communication layer for Web3, and how it uses Zero Knowledge proofs to stay private and function better. We've also looked at Zerokit and how we can make it easier to do ZKP in different environments.
Finally we also looked at some other research we've been doing. All of the things mentioned in this article, and more, is available as write-ups, specs, or discussions on our forum or Github.
If you find any of this exciting to work on, feel free to reach out on our Discord. We are also hiring, and we have started expanding into other privacy infrastructure tech like private and provable computation with ZK-WASM.